╰─ pdfinfo $HOME/fuzz_main/exercise1/fuzzing_xpdf/pdf_examples/helloworld.pdf Custom Metadata: no Metadata Stream: no Tagged: no UserProperties: no Suspects: no Form: none JavaScript: no Pages: 1 Encrypted: no Page size: 200 x 200 pts Page rot: 0 File size: 678 bytes Optimized: no PDF version: 1.7
rm -fr $HOME/fuzz_main/exercise1/fuzzing_xpdf/install/ cd$HOME/fuzz_main/exercise1/xpdf-3.02/ make clean
使用afl-clang-fast编译器构建 xpdf:
1 2 3 4
export LLVM_CONFIG="llvm-config-11" CC=$HOME/AFLplusplus/afl-clang-fast CXX=$HOME/AFLplusplus/afl-clang-fast++ ./configure --prefix="$HOME/fuzz_main/exercise1/fuzzing_xpdf/install/" make make install
[!] Stopped during the first cycle, results may be incomplete. (For info on resuming, see /usr/local/share/doc/afl/README.md) [*] Writing ./out/default/fastresume.bin ... [+] fastresume.bin successfully written with 763463 bytes. [+] We're done here. Have a nice day!
╰─ $HOME/fuzz_main/exercise1/fuzzing_xpdf/install/bin/pdftotext ./out/default/crashes/id:000000,sig:11,src:001110,time:252252,execs:138241,op:havoc,rep:13 $HOME/fuzz_main/exercise1/fuzzing_xpdf/output Error (18145): Illegal character ')' Error: PDF file is damaged - attempting to reconstruct xref table... [1] 471912 segmentation fault $HOME/fuzz_main/exercise1/fuzzing_xpdf/install/bin/pdftotext
可以看到存在崩溃。
调试
重新编译带源码的文件:
1 2 3 4 5 6
rm -fr $HOME/fuzz_main/exercise1/fuzzing_xpdf/install/ cd$HOME/fuzz_main/exercise1/xpdf-3.02/ make clean CFLAGS="-g -O0" CXXFLAGS="-g -O0" ./configure --prefix="$HOME/fuzz_main/exercise1/fuzzing_xpdf/install/" make make install
GNU gdb (Ubuntu 15.0.50.20240403-0ubuntu1) 15.0.50.20240403-git Copyright (C) 2024 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty"for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration"for configuration details. For bug reporting instructions, please see: <https://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>.
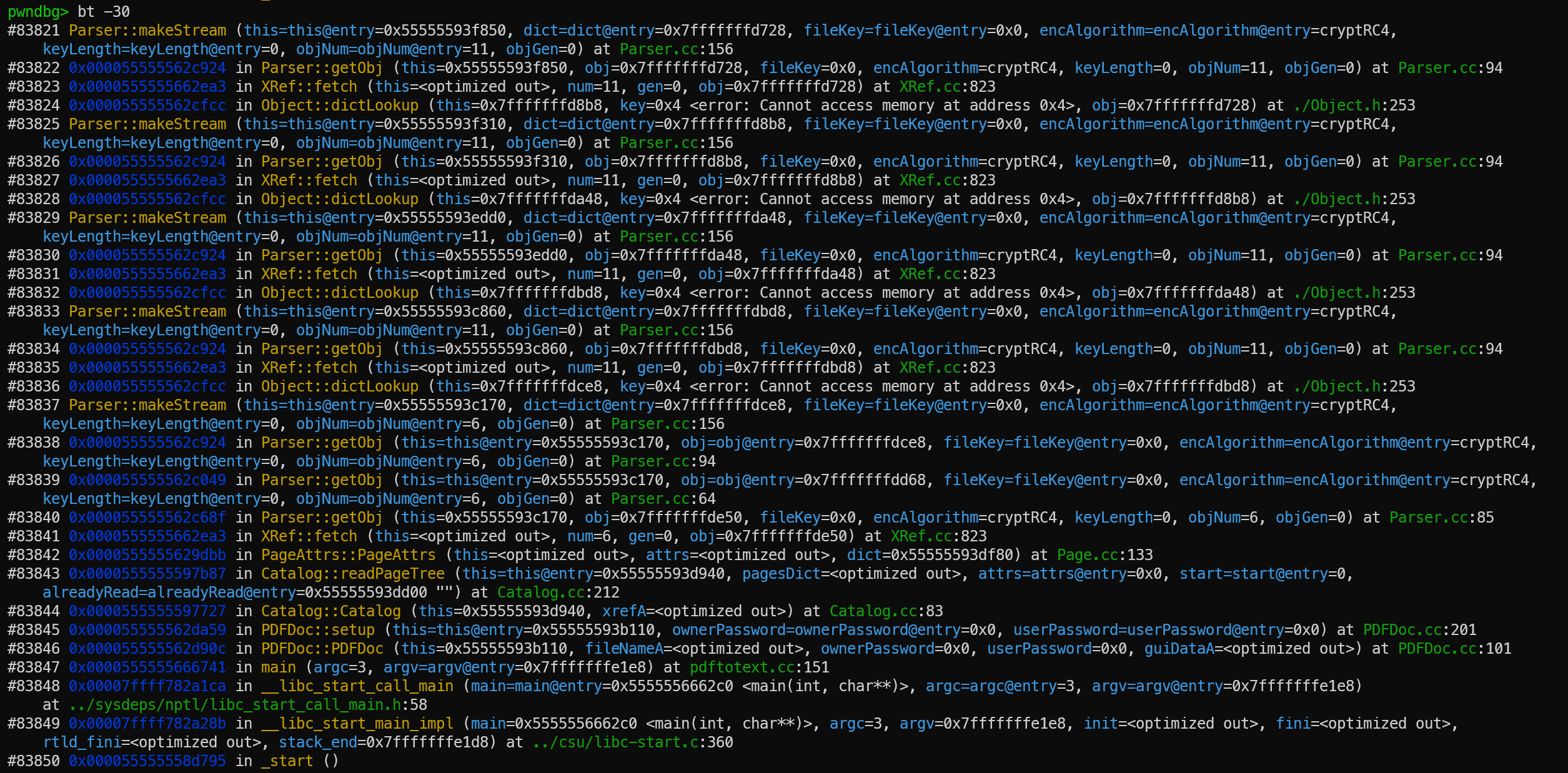
For help, type"help". Type "apropos word" to search for commands related to "word"... pwndbg: loaded 175 pwndbg commands and 47 shell commands. Type pwndbg [--shell | --all] [filter] for a list. pwndbg: created $rebase, $base, $hex2ptr, $bn_sym, $bn_var, $bn_eval, $ida GDB functions (can be used with print/break) Reading symbols from /home/zlsf/fuzz_main/exercise1/fuzzing_xpdf/install/bin/pdftotext... ------- tip of the day (disable with set show-tips off) ------- Want to NOP some instructions? Use patch <address> 'nop; nop; nop' pwndbg> r Starting program: /home/zlsf/fuzz_main/exercise1/fuzzing_xpdf/install/bin/pdftotext /home/zlsf/fuzz_main/exercise1/fuzz/out/default/crashes/id:000000,sig:11,src:001110,time:252252,execs:138241,op:havoc,rep:13 /home/zlsf/fuzz_main/exercise1/fuzzing_xpdf/output [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Error (18145): Illegal character ')' Error: PDF file is damaged - attempting to reconstruct xref table...
Program received signal SIGSEGV, Segmentation fault. 0x00007ffff78ac4d9 in _int_malloc (av=av@entry=0x7ffff7a03ac0 <main_arena>, bytes=4) at ./malloc/malloc.c:4460 warning: 4460 ./malloc/malloc.c: No such file or directory LEGEND: STACK | HEAP | CODE | DATA | WX | RODATA ──────────────────────────────────────────────────────────────[ REGISTERS / show-flags off / show-compact-regs off ]─────────────────────────────────────────────────────────────── RAX 0x17d41 RBX 0x20 RCX 0x55555742b2c0 ◂— 0 RDX 0x21 RDI 0x55555742b2b0 ◂— 0 RSI 4 R8 0x7ffff7a03b20 (main_arena+96) —▸ 0x55555742b2c0 ◂— 0 R9 0x20 R10 1 R11 0 R12 0x7ffff7a03ac0 (main_arena) ◂— 0 R13 4 R14 0x55555742b2b0 ◂— 0 R15 0x20 RBP 0x7fffff7ff060 —▸ 0x7fffff7ff0a0 ◂— 1 RSP 0x7fffff7fefe0 RIP 0x7ffff78ac4d9 (_int_malloc+3945) ◂— call alloc_perturb ───────────────────────────────────────────────────────────────────────[ DISASM / x86-64 / setemulate on ]──────────────────────────────────────────────────────────────────────── ► 0x7ffff78ac4d9 <_int_malloc+3945> call alloc_perturb <alloc_perturb> rdi: 0x55555742b2b0 ◂— 0 rsi: 4